URI(Uniform Resource Identifier)는 URL(Uniform Resource Locator)과 URN(Uniform Resource Name)을 포함하는 개념이다.
URL은 실제의 네트워크 경로를 가리키며, 네트워크 상의 리소스 접근기에 사용된다. URL의 첫 번째 부분은 다음과 같은 프로토콜을 명시하는데, http, ftp 등이 있다. URL프로토콜 부분을 scheme이라고 한다. Scheme 뒤에는 콜론(:)이 따라오며 그 뒤에 식별된 자원의 경로가 나타난다.
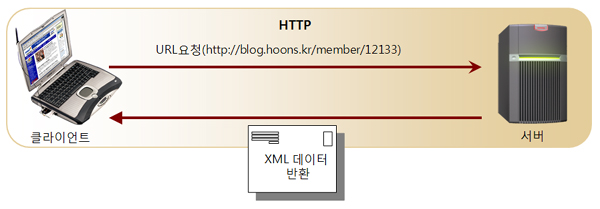
이 URL은 www.xmlgo.net이라는 이름의 인터넷 상에 있는 서버로 부터 /document/editor/editor.html이라는 파일을 검색하기 위한 경로(PATH)이다. 파일 editor.html은 /document/editor라는 디렉토리에 있으며, HTTP 프로토콜에 의해 검색되어야 한다.
URN은 자원에 대하여 영속적(persistent)이고 유일하다. 위치에 독립적인 이름을 제공하기 위하여 존재한다. 이것은 RFC 2141 (http://www.ietf.org/rfc/rfc2141.txt)에 정의되어 있다. iURN은 문자열 “urn” 혹은 “URN”, NID(Namespace Identifier), 그리고 NSS(Namespace Specific String)로 구성되어 있으며 각 구성 엘리먼트 간에 콜론(:)을 위치시킨다. NID는 URN의 형태를 나타내는데, 예를 들어 차후 XMLgo.net에서 ebXML문서의 형태로 각 회사의 정보를 기억해 두는 저장소를 URN으로 가리키고, NSS는 유일하고 영속적이어야 하며, 여기서는 registry1이라고 칭하였다.
urn:xmlgo:registry1
좀 더 현실적인 예를 들어 본다면
한국인을 위한 URN을 만들기 위하여 한국–시민 이라고 선언할 수 있다. NSS로는 유일한 번호, 주민등록번호를 표현하도록 한다면 000000-0000000이 된다.
urn:한국–시민:000000-0000000
지금까지의 내용을 종합해 보면, Namespace를 지정할 때 URI로 지정한다. URI로는 현재 널리 사용하는 웹주소, URL방식과 URN방식이 포함되어 있다. 일반적으로 URL을 많이 사용하나 URN도 널리 사용 될 것이다. URL에서는 도메인 주소와 거기에 위치한 물리적인 경로가 자원을 찾기 위한 중요한 정보가 되지만, URN은 자원에 부여된 고유한 이름으로 그 자원의 위치와는 무관하게 부여된 이름이다.
이를 구체적으로 예를 들면 , 인천 광역시 남구 용현동에 인하대학교가 있지만, 인하대학교는 새로운 부지로 이사를 갈 수도 있을 것이다. 인하대학교가 어디에 있는지는 URL(주소)로 표현 할 수 있지만, 인하대학교가 다른 곳으로 가더라도 URN을 가지고 그 리소스(인하대학교)을 식별할 수 있다. 이사를 가고 나서 ‘인천광역시 남구 용현동의 인하대학교’ 라는 기존의 주소를 가지고는 인하대학교를 찾을 수 없다. 하지만 인하대학교란 고유한 이름은 변함이 없을 것이다.
인터넷 업계는 OpenAPI의 열풍이 불고 있다. 너도나도 OpenAPI를 공개하고 있고 사용자들에게 다양한 방식의 사용을 기대하고 있다. 최근 이 OpenAPI와 함께 거론되는 기술을 당연 REST이다. 구글, 아마존, 네이버 모두가 OpenAPI를 REST 방식으로 지원한다. (물론 기존의 SOAP 방식도 지원한다.)
그렇다면 REST란 과연 어떤것일까? W3C 표준이 아님에도 불구하고 업계의 사랑을 받는 이유는 무엇일까? 이 궁금증을 풀기위해 본 포스트를 작성하고자 한다.
1) 정의 + REST는 ROA를 따르는 웹 서비스 디자인 표준이다. – ROA : Resource Oriented Architecture
+ REST 방식의 웹서비스는 세션을 쓰지 않는다는 거다.
기존의 서블릿 개발에서는 세션을 이용해서 인증 정보들을 가지고 다닌다. 개발자의 개념(?)에 따라서는 파라미터까지 마구마구 집어넣어서 사용하기도 한다. 이 때문에 요청 처리가 너무너무 무거워진다.
또한 요청간의 전후 관련성이 생기기 때문에 한 세션의 일련의 요청은 무조건 하나의 서버가 처리해야 한다. 그래서 로드발란싱을 위해 고가의 로드발란싱 서버가 필요하게 된다.
하지만 REST는 세션을 사용하지 않기 때문에 각각의 요청을 완벽하게 독립적이다. 따라서 각각의 요청은 이전 요청과는 무관하게 어떠한 서버라도 처리할 수 있게 된다. 즉! 로드발란싱이 간단해 질 것이라는 것이 느낌이 오는가? (물론 인증 관련해서는 복잡한 문제가 생긴다.)
3) ROA의 정의 + ROA는
– 웹의 모든 리소스를 URI로 표현하고
– 모든 리소스를 구조적이고 유기적으로 연결하여
– 비 상태 지향적인 방법으로
– 정해진 method만을 사용하여 리소스를 사용하는
아키텍쳐 이다.
+ 이는 4가지의 고유한 속성과 연관되어 진다.
– Addressablilty
– Connectedness
– Statelessness
– Homogeneous Interface
+ 여기서 잠깐! 정리하자면 REST란 위에 언급한 4가지 속성을 지향하는 웹서비스 디자인 표준이다.
4) RESTful 웹 서비스 속성 (ROA 속성) + Addressablilty (주소로 표현 가능함) – 제공하는 모든 정보를 URI로 표시할 수 있어야 한다.
– 직접 URI로 접근할 수 없고 HyperLink를 따라서만 해당 리소스에 접근할 수 있다면 이는 RESTful하지 않은 웹서비스이다.
– 예를 들면, GMail은 모든 메일 리소스는 하나의 URI와 연결되어 있다. (http://mail.google.com/mail/?hl=ko#sent/1036854d04d6de9e) 하지만 코리아닷컴의 경우에는 http://mbox07.korea.com/mail/mailView.crd 라는 주소에 접근한 후에 페이지에 표시된 메일의 링크를 통해서만 접근이 가능하다. (특정 회사를 지칭해서 유감입니다. 관계자 분들은 이해 부탁드립니다.) 둘 간의 차이가 이해가 되십니까?
+ Connectedness (연결됨) – 일반 웹 페이지처럼 하나의 리소스들은 서로 주변의 연관 리소스들과 연결되어 표현(Presentation)되어야 한다.
– 예를 들면,
<user>
<name>MK</name>
</user> 는 연결되지 않은 독립적인 리소스이다.
<user>
<name>MK</name>
<home>MK/home/</home>
<office>MK/office</office>
</user> 는 관련 리소스(home, office)가 잘 연결된 리소스의 표현이다.
+ Statelessness (상태 없음) – 현재 클라이언트의 상태를 절대로 서버에서 관리하지 않아야 한다.
– 모든 요청은 일회성의 성격을 가지며 이전의 요청에 영향을 받지 말아야 한다.
– 다시 또 코리아닷컴의 예를 들면 메일을 확인하기 위해 꼭 ‘..코리아닷컴../mailView.crd’에 접근하여 해당 세션을 유지한 상태에서 메일 리소스에 접근해야 한다. 이것이 바로 Statelessness가 없는 예이다.
– 세션을 유지 하지 않기 때문에 서버 로드 발란싱이 매우 유리하다.
– URI에 현재 state를 표현할 수 있어야 한다. (권장사항)
+ Homogeneous Interface (동일한 인터페이스)
– HTTP에서 제공하는 기본적인 4가지의 method와 추가적인 2가지의 method를 이용해서 리소스의 모든 동작을 정의한다.
– 리소스 조회 : GET
– 새로운 리소스 생성 : PUT, POST (새로운 리소스의 URI를 생성하는 주체가 서버이면 POST를 사용)
– 존재하는 리소스 변경 : PUT
– 존재하는 리소스 삭제 : DELETE
– 존재하는 리소스 메타데이터 보기 : HEAD
– 존재하는 리소스의 지원 method 체크 : OPTION
– 대부분의 리소스 조작은 위의 method를 이용하여 대부분 처리 가능하다. 만일 이것들로만 절대로 불가능한 액션이 필요할 경우에는 POST를 이용하여 추가 액션을 정의할 수 있다. (되도록 지양하자)
5) 정리 REST는 . 웹의 모든 리소스를 URI로 표현하고 . 이를 구조적이고 유기적으로 연결하여 . 비 상태 지향적인 방법으로 . 일관된 method를 사용하여 리소스를 사용하는 웹 서비스 디자인 표준이다.
SOAP은 SOAP메세지를 이용하여 특정한 서비스를 요청한다. SOAP 메세지를 사용해야 하기 때문에 무겁다고 말하고 서비스를 요청하기 때문에 SOA와 가깝다.
REST는 URI를 이용해서 리소스를 요청한다. URI를 사용하기 때문에 가볍다고 말하고 리소스를 요청하기 때문에 ROA와 가깝다.
SOA와 ROA에 대한 관점은 시각에 따라 다를 수 있지만 극명하게 대조하기 위해서는 위와 같이 차이점을 이해하는 것이 가장 좋다고 생각된다.
7) 맺음말
최대한 쉽게 작성하고자 했지만 여전히 MK 본인에게도 설명하기 어려운 것은 사실이다. 하지만 중요한 것은 REST는 아키텍쳐가 아니라는 사실이다. ROA라는 아키텍쳐를 반영한 디자인 철학이다. ROA의 4가지 중요한 속성을 잘 이해한 후 이를 가슴에 깊이 새기고 이를 어기지 않고 웹 서비스를 디자인하면 이것이 바로 RESTful 한 웹 서비스가 될 것이라는 것이다. 다음 포스트에서는 REST 구현체들에 대해 생각해 볼 예정이다. .net, java, ruby on rails에서 각각의 접근 방식에 대해서 좀 더 구체적으로 알아보도록 하자.
병행성 분야에서는 주류언어에 속한다. CouchDB, SimpleDB, Riak 등 NoSQL DB에서 맵리듀스의 구현 혹은 DBMS의 전체 구현을 위해 많이 사용되며, 채팅과 메시징, WhatsApp서버, 리그오브레전드 서버, 금융시스템, 게임서버[11]와 같은 분야에 이용된다. 이 중 WhatsApp의 사용 사례가 유명한데, 12코어(24 논리코어) 프로세서, 100GB 메모리의 하드웨어로 실 서비스에서 서버당 200만건 이상의 연결을 받고 있다.
Ericsson은 스웨덴 무선통신 전문 업체
주된 차이
Erlang
Golang
언어의 분류
함수형
절차형
형
동적 형(dialyzer에 의한 형 검사 있음)
정적 형
변수
immutable
mutable
예외에 관한 사상
Let it crash
Defensive Programming
병행 처리 모델
Message Passing
(Actor Model)
Message Passing
(CSP/π caluculus)
각각의 프로세스 차이
Erlang
Golang
워커 쓰레드 수
default로 CPU 코어 개수
default로 1
(기본적으로는 CPU 코어 개수로 지정)
초기 스택
309 words
(1words≒ 64bit)
8k bytes
프로세스 간 메모리 공유
없음
있다(global변수)
프로세스 수 상한
디폴트 32768
최대 268435456
몇 10만 가능
프로세스 실행
워커 스레드와 바인드 하지 않는다
(고정하는 것도 가능)
워커 스레드와 바인드 하지 않는다
※ 프로세스(Erlang Process/goroutine )
병행 처리 모델의 차이
이 부분을 쓰는데 arild씨의 슬라이드를 참고하였다. 그림이 매우 알기 쉬우므로 이쪽도 참조해 주길 바란다.
Erlang: Actor model
Process(Actor)가 Mailbox를 1개 가진다
통신은 어느 Process로 보낼지 명확
블록
수신 측: Mailbox가 빈 경우 블록
송신 측: 블록 하지 않는다
Golang: CSP (Communication Sequential Processes)
Channel을 공유하고 통신을 한다
Channel과 Process는 다 vs다 관계(어떤 프로세스가 받을지 모른다.)
블록
송신 측과 수신 측이 갖추어지지 않으면 안 된다
※Golang은 Channel사이즈를 지정할 수 있기 때문에 사이즈>0의 경우는 Channel이 비거나/다 찬 경우에만 차단
스케쥴러
대량으로 Process를 실행하는 경우 어떻게 실행되느냐에 차이가 있다.
Erlang
모든 Process를 균등하게 실행하려고 한다.
Golang
일정 시간까지는 1개(코어 수 만큼)의 Process를 실행한다(ver1.2까지는 Process가 sleep/종료까지 계속 실행하였다)
Meetup is the world’s largest network of local groups. Meetup makes it easy for anyone to organize a local group or find one of the thousands already meeting up face-to-face. More than 9,000 groups get together in local communities each day, each one with the goal of improving themselves or their communities.
Meetup’s mission is to revitalize local community and help people around the world self-organize. Meetup believes that people can change their personal world, or the whole world, by organizing themselves into groups that are powerful enough to make a difference.
워드프레스는 HTML에 대한 지식 없이도 워드프레스에서 제공하는 매뉴얼만 익히면 쉽게 홈페이지를 구축하실 수 있습니다. 키워드 검색은 블로그에서도 가능한데 굳이 홈페이지 구축을 해야하냐고 생각하실 수 있지만 워드프레스는 ‘플러그인’으로 회원가입, 소셜 연동, 이벤트, 갤러리, 방문자 통계, 게시판 등 다양한 홈페이지 테마를 제공 받을 수 있습니다. 광고를 해야할 때 드는 추가적 비용과 과정 없이 구글 등 전세계의 검색엔진에 자동으로 노출됩니다.
매뉴얼과 초기 홈페이지 설치하는데 드는 시간을 제외하고 블로그 운영에서 광고에 드는 시간 비용 등을 비교한다면 워드프레스가 절약˙단축된 자원으로 큰 효과를 볼 수 있습니다.
실제로 하버드 대학, 내셔널 지오그래피의 홈페이지는 워드프레스로 만들었으며, 현재 우리나라의 S사와 L사 역시 워드프레스로 홈페이지를 구축했습니다.
약간의 시간 투자로 얻을 수 있는 다른 장점들을 생각하면 워드프레스를 무시할 수 없는 것 같습니다.
사설이 길었네요. 이제부터가 본론입니다. 제가 오늘 소개할 녀석은 클라우드 컴퓨팅에 있어 “자르는” 축을 담당하는 가상화의 떠오르는 아이돌, LXC를 사용한 docker 입니다. LXC가 무엇인지는 여기서 중요하지 않습니다#2. 그냥 업계의 떠오르는 아이돌 정도로 해 둡시다. 그러니까 아이유 같은 존재죠.
docker가 등장한 배경을 설명하자면 이렇습니다. Heroku와 함께 PaaS계에서 끗발을 날렸던 dotCloud는 어느 날 갑자기 충격적인 발표를 합니다. 자기네들이 쓰는 가상화 및 애플리케이션 플랫폼을 공개해 ‘오픈 소스로’ 제공하겠다는 것이죠. 아니, 이럴 수가! 이러시면… 이러시면 정말 감사합니다#3!
docker의 가장 큰 특징은 다음과 같이 요약할 수 있습니다.
image 관리의 간편화와 container 관리 간편화
어떤 서비스를 돌리기 위해서는 필요한 서버들이 있습니다. 데이터베이스 서버, 웹 서버, 캐시 서버, 워커 서버 따위의 것들이죠. 이 모든 걸 한 군데로 퉁쳐서 모을 수도 있겠지만 그렇게 되면 데이터베이스, 웹, 캐시, 비동기 업무를 위한 설정과 프로그램들을 한 군데로 모아 관리해야 합니다. 그렇게 되면 설정이 복잡해지거나 애플리케이션이 거대해지거나 필요할 때 횡적인 확장을 하기가 어려워집니다.
예를 들어 웹서버에서는 A라는 라이브러리의 1버전을 필요로 하는데 데이터베이스 서버에서는 2버전을 필요로 한다던지, 이벤트 하느라 접속자가 너무 증가했는데 다른 웹서버가 한시간 정도만 필요한 일을 그럴 수 없어서 서버를 통째로 하나 사야 한다던지 하는 일들이죠. docker는 그런 상황에 유연하게 대응하기 위해 서버 설정과 필요한 프로그램들을 따로 관리할 수 있는 환경을 제공합니다.
docker는 이렇게 분리된 환경을 image라고 부르며, 이 image를 기반으로 여러 개의 container를 생성할 수 있습니다. 음… 이렇게 이해하시면 편할 것 같습니다. image는 유전자 설계도고, container는 그 유전자 지도에서 만들어진 생물체라고나 할까?
즉, 이 설계도를 관리하면 필요할 때 목적에 적합하게 만들어진 생물체를 얼마든지 만들어낼 수 있게 되죠. 필요할 때는 설계도의 설계를 바꿔서 새로운 생물체를 만들어낼 수도 있습니다. 단순하지만 docker의 가장 커다란 컨셉이고 강력하기까지 합니다. 이렇게 단순하고 간편한 환경은 여러 가지 시도를 가능하게 합니다.
오토스케일링(웹서버가 필요할 때 웹서버를 막 찍어낸다던가!)
유연한 배포 정책(서버를 최신 버전으로 업데이트했는데 버그가 있어서 재빨리 옛날 버전으로 돌아가야 한다던가!)
자원의 효율적인 활용(이 쪽 서버가 놀고 있으니까 여긴 웹서버 두개 정도 더 띄운다던지)
거기다 수고를 좀 더 들이면, docker의 API를 활용해 Heroku 부럽지 않은 웹 GUI PaaS 서비스를 만들 수 있을지도 모릅니다(만들어 주시면 감사히 쓰겠습니다).
Paypal이 Java를 버리고, node.js로 서버를 변경했다고 합니다. 기사에 링크된 페이팔 블로그 링크에 옮겨간 이유가 나옵니다. 여러 이유가 있겠지만, 서버에서 프론트까지 같은 언어로 커뮤니케이션하는 것이 좋다고 판단했다는 이유가 눈에 띕니다.
“It unifies our engineering specialties into one team which allows us to understand and react to our users’ needs at any level in the technology stack.”
오래 전부터 프로토타이핑을 해왔고, 올해부터 서비스에 적용했다고 합니다. 웹 애플리케이션 프레임워크로 express를 쓰고, Grunt 작업 실행기와 설정을 위해서 nconf를 사용했다고 zdnet이 전합니다.
왜 Node 인가?
이벤트 중심인 Node.js 또는 Node는 프로그래머가 Evetned, non-blocking I/O 주도 접근법을 사용하여 웹 어플리케이선의 코드를 작성할 수 있게 해준다. Node는 구글의 엄청나게 빠른 V8 자바스크립트 엔진을 기반으로 만들어졌다. 이 자바스크립트 엔진은 매우 빠른 동적 프로퍼티 접근, 머신코드의 동적 생성, 고효율 가비지 컬렉션으로 잘 알려져 있다. 이 자바스크립트 엔진은 Node.js가 끔찍하게 빠른 속도로 실행될수 있게 한다. 그러므로, Node는 비동기 입출력을 수행하는데 정말로 빠르다(네트워크, 서버의 하드디스크, 데이터베이스 입출력이나 파일 업로드하는 경우)
Node가 매우 빠르고, non-blocking 입출력을 제공한다는 것 외에도, Node는 싱글 쓰레드 / 이벤트 루프에 기반들 둔다. 그리고 그것은 Node.js의 장점이 되는 또다른 주요한 요소이다.
Node.js에서 Single thread / Event loop는 무엇을 의미하는가?
가장 잘 알려진 웹 서버인 아파치와 NGINX가 동시 접속을 어떻게 처리하는지 이해해보자.
아래에 두 웹서버를 비교하는 벤치마크가 있다.
*Note: 위의 벤치마크는 실제 상황의 예제가 아니다. 로컬호스트에서 스태틱 파일을 다룬 결과이다.
위의 벤치마크는 실제 상황과 같지는 않지만 두 서버의 성능 통계를 잘 보여준다. 아파치와 NGINX 초당 매우 많은 수의 요청을 처리할 수 있는 것처럼 보이지만, 동시 요청의 수가 증가함에 따라, NGINX에 비해 아파치의 성능이 크게 떨어지는 것을 볼수 있다. 그리고 NGINX는 여전히 동시 접속수가 증가할때에도 성능의 저하가 없이 거의 같은 속도를 유지한다.
같은 벤치마크에 대해서, 두 서버의 메모리 사용에 관한 관점에서 본 그래프를 살펴보자.
*Note: 위의 벤치마크는 실제 상황의 예제가 아니다. 로컬호스트에서 스태틱 파일을 다룬 결과이다.
위 그래프는 증가하는 동시 요청수에 대한 두 서버의 메모리 사용을 나타낸다. 두 서버 모두 많은 수의 동시 접속을 처리할 수 있지만 서버의 자원, 즉 메모리 사용에는 눈에 띄는 큰 차이가 있다. 그래프를 보면 아파치가 NGINX보다 같은 동시 요청 수에 대해 훨씬 더 많은 양의 메모리를 사용한다는 것은 분명하다. NGINX는 동시 요청을 매우 효율적인 이벤트 루프 – 싱글 쓰레드 방식으로 처리한다. 반면에 아파치는 복수 개의 쓰레드를 (각 접속 당 하나) 쏟아낸다. 이 쓰레드들이 많은 양의 메모리를 사용하고, 그 결과 서버에 많은 수의 동시 요청이 발생할 경우 아파치는 정말 비효율적이게 된다. NGINX는 접속 당 새로운 쓰레드를 실행하는 대신에 이벤트 루프를 사용함으로써 매우 안정적으로 유지된다.
Context swithcing은 쉽지가 않았다, 실제 상황에서 테스트 했을 때, 두 서버 모두 자원을 사용하고 증가 된 응답 시간을 보였다. 그러므로, 대규모 동시성에 대해서는, 새로운 쓰레드들을 운영체제에 쏟아낼 수가 없다. 이를 처리하기 위해서, 싱글 쓰레드 실행에 기반을 둔 Node는 서버에 만들어지는 모든 새로운 리퀘스트를 처리하기 위해 복수개의 쓰레드를 실행하는 대신에 이벤트 루프를 사용한다. 그리고 이것은 context switching에서 어떤 자원도 낭비하지 않음으로써 Node.js를 매우 강력하게 만든다. 따라서, Node.js는 대규모 동시성을 처리할 때나 가장 저 레벨 베이스를 제공할 때 매우 효율적이기 때문에 그 결과 프로그래머들은 Node 위에서 스트림을 할 수 있고 데이터를 버퍼에 저장할 필요가 없다. 단지 이것만이 아니라, Node.js는 프로그래머가 이벤트 기반 알고리즘으로 코드를 짤수 있게 해준다. Node.js는 또한 개발자들이 코드와 업무를 병렬로 실행하는데 힘을 실어주며 non-blocking 입출력을 제공한다. 아키텍쳐적 이점들을 가지는것 외에도, Node(매우 빠른 구글의 V8 자바스크립 엔진 기반으로 만들어진)는 Node.js를 빛처럼 빠르게 만든다.
Why Node.js over Others available?
Node.js를 사용하기 전에 다른 방법들을 알아보고 왜 이벤트 기반 접근법이 오늘날 프로그래머들 사이에서 잘 알려지지 않았는지 알아보자. 이것에 관한 세가지 기본적인 이유가 있다.
문화적 선입견 : 첫 번째 이유는 non-blocking 입출력을 사용하는 것에 대한 문화적 선입견이다. 어느 언어를 배우든지 맨 처음으로 짜보는 프로그램은 다음과 같다.
1
2
3
4
5
6
7
//문자열 출력
puts("Please Enter Your Green Name");
//입력을 받기 위해 대기
vargreen_name=gets();
//문자열 출력
puts("Your Green Name is: "+green_name);
위의 코드는 입력 요구 알고리즘을 기반으로 한다. 코드를 짜는 이런 접근법은 코드를 막아(blocking)버린다. 위의 코드에서 사용자는 ‘green name’을 입력하도록 요구 받고 사용자가 입력할 때까지 기다린다. 코드가 멈춰버린다! 이 코드는 사용자가 ‘green name’을 입력할 때 까지 어떤 것도 할 수가 없다.
만약 같은 코드를 다음과 같이 작성한다면..
1
2
3
4
5
6
7
8
//문자열 출력
puts("Please Enter Your Green Name");
//콜백 함수 정의
gets(function(green_name) {
puts("Your Green Name is: "+green_name);
});
//기다리지 않고 다른 일을 처리한다.
이것은 이벤트 기반의 프로그래밍 접근법이다. 이 프로그래밍 접근법을 사용함으로써 프로그래머들은 evented non-blocking I/O를 얻을 수 있다. 이런 유형의 프로그래밍 접근법이 막기 – 멈추기 – 코딩 접근법 처럼 잘 알려지지 않은 유일한 이유는 사람들이 이런 방식의 코딩 접근법이 어렵고 더 복잡하다고 생각하기 때문이다(실제로는 사실이 아니다). 그래서, 이벤트 주도 방식으로 어플리케이션을 코딩하는 것에 대한 선입견이 존재한다.
부족한 인프라 : Node의 방식으로 코딩을 하지 않는 또 다른 이유는 인프라의 부족이다. 만약 당신의 코드가 이벤트 중심으로 작동할 필요가 있다면, 절대 입출력을 막아서는 안되고, 당신의 코드가 싱글 쓰레드에 기반일 때 데이터베이스가 응답하는 것을 기다릴 수가 없고, 멈출 수도 없다. 대부분의 프로그래밍 라이브러리들은 이벤트 주도 프로그래밍 접근법을 지원할 수가 없다. 예를 들어: POSIX는 비동기 I/O를 지원하지 않는다. 지원하는 다른 것들은 같은 것을 얻기 위한 충분한 메뉴얼을 제공하지 않는다. C는 클로저와 익명 함수를 가지고 있지 않다. MySQL는 비동기 커넥션을 지원하지 않는다. 기타 등등. 이것들이 이벤트형 코드를 짜는데 어렵게 만든다.
너무 많은 인프라 : 이벤트 주도 프로그래밍을 위한 플랫폼을 제공하는 라이브러리들이 있다. 루비의 Event Machine. 파이썬의 Twisted, Qt의 이벤트 루프가 그들이다. 비록, 이런 라이브러리들이 이벤트 프로그래밍을 위한 플랫폼에 non blocking I/O를 제공하고, 이 라이브러리들을 사용하면 효율적인 서버를 짜는 것이 상대적으로 간단할지라도, 사용자들은 이들을 어떻게 사용해야 할 지를 자주 헷갈려하는 경향이 있다. 예를 들어, 루비로 개발할 때 많은 라이브러리들을 가지고 있지만, 루비의 이벤트 머신 라이브러리는 MySQL 라이브러리와 조합될 수가 없다. 왜냐하면 모든 쿼리를 막아버리기 때문이다.
다행스럽게도, Node를 사용한다면 이벤트 기반 어플리케이션을 개발이 더 이상 어려운 일이 아니다. Node는 매우 효율적이고, 순수한 이벤트 기반,non-blocking 웹 어플리케이션을 만들기 위한 인프라를 제공하고, 동시성 문제를 매우 효과적으로 처리할 수 있다. 이는 Node가 CommonJS 모듈시스템을 사용하고, non-blocking I/O를 제공하며, 구글에서 개발한 미친 스피드의 V8 자바스크립트 엔진에서 돌아가기 때문이다. Node.js는 이벤트 기반 프로그래밍을 정말 쉽고, 매우 효율적이고, 빛과 같이 빠르게 만든다.